Tercer Milenio
En colaboración con ITA
Big data
Data lakes, lagos donde flotan los datos
Pescando datos al borde de un lago. Podría ser la imagen para entender lo que son los ‘data lakes’, almacenes únicos de datos fáciles de gestionar y compartir. Contienen enormes cantidades de datos ‘crudos’, sin procesar, pero descritos mediante metadatos. De esa manera, podemos tenerlos totalmente disponibles bajo demanda y, además, descubrir, analizar y generar informes.
Uno de los desafíos tecnológicos a los que se enfrentan las empresas es el crecimiento de los datos: cada dos años se duplica la cantidad de datos gestionados. Terabytes, petabytes y hexabytes son ya términos de uso común, en todos los sectores, cuando hablamos de capacidad de almacenaje. A este hecho se añaden otros dos: alrededor del 80% de esos datos es información no estructurada (textos, vídeos, etc.) y al menos el 50% de los datos gestionados por la empresa (de su ‘know-how’) se almacena y gestiona fuera de sus centros de datos, sin protección y creando brechas de seguridad.

Frente a los repositorios tradicionales, aparecen los ‘data lakes’. Un ‘data lake’ es un conjunto centralizado de repositorios de datos capaz de contener vastas cantidades de datos crudos (sin procesar) –tanto estructurados (bases de datos convencionales) como no estructurados–, descritos mediante metadatos (que identifican el conjunto de datos al que pertenece cada dato) y que hace disponibles los datos bajo demanda. Además, un ‘data lake’ permite descubrir, analizar y generar informes de los datos que contiene.
Un ‘data lake’ puede contener información de registros de servidores y aplicaciones, de sensores de datos (internet de las cosas), datos de bajo nivel procedentes de consumidores (por ejemplo, clics en una web), datos de redes sociales, colecciones de documentos (mails, manuales de usuario, informes, etc.), datos de geolocalización y geolocalizados, imágenes, vídeo, audio, fotos...
¿Cuántos datos puede contener un ‘data lake’? Su capacidad de almacenamiento es escalable y puede ir creciendo de manera masiva (con plataformas como Hadoop o Apache Spark, entre otros).
La consulta y búsqueda de datos se realiza con tecnologías tradicionales de bases de datos (en datos estructurados) o utilizando vías alternativas como indexación (de texto, vídeo, audio) y bases de datos NOSQL. Además, de manera sencilla sus datos se hacen disponibles para usuarios sin conocimientos técnicos profundos.
Frente a los Datawarehouse y Data Marts tradicionales, un ‘data lake’ no describe el formato de los datos hasta que se necesitan. Retrasar la categorización de los datos, desde el punto de su captura hasta su punto de uso, permite realizar operaciones analíticas que trascienden un esquema ya adoptado.
Paso a paso
Aunque no existe una metodología estándar, el proceso de creación de un ‘data lake’ debería considerar los siguientes pasos:
- Adquisición de datos Obtención de datos y metadatos, así como su preparación para ser incluidos en el ‘data lake’. Este proceso puede ser muy exigente y requiere conocer el uso que se quiere dar a los datos para anticipar las necesidades de los usuarios. Tras identificar las fuentes y los datos a obtener, deberán determinarse los términos y condiciones bajo los que están licenciados.
- Data Curation/Grooming Data Los datos crudos son transformados en datos consumibles por las aplicaciones analíticas.
- Provisión de datos Procesos que permiten acceder a los datos contenidos en el ‘data lake’ de acuerdo con las políticas establecidas.
- Preservación de los datos Procesos y políticas que determinan qué datos deben conservarse y hasta cuándo y cuáles no.
De predecir errores a hacer agricultura de precisión
Desde el Instituto Tecnológico de Aragón se contribuye a generar ‘data lakes’ en proyectos tanto de investigación como de aplicación, para clientes de distintos sectores y, utilizando los datos allí incluidos para alcanzar distintos objetivos.
Entre otros muchos proyectos, algunos ejemplos son:
- Shion-Cloudifacturing (Horizonte 2020): despliega en la nube un sistema de predicción de errores en la inyección de plásticos basado en las datos de las máquinas de la empresa zaragozana Thermolympic capturados por un sistema de visión artificial.
- Avisan: es un proyecto en el Itainnova participa desarrollando una herramienta de monitorización y análisis de redes sociales para determinar qué temas relacionados con el ámbito de la alimentación saludable están candentes en cada momento.
- Agrolake: el objetivo de este proyecto desarrollado para la empresa cincovillesa Paintec, que se dedica a la teledetección agrícola con drones, es capturar la información relevante para la gestión de explotaciones agrarias aplicando agricultura de precisión.
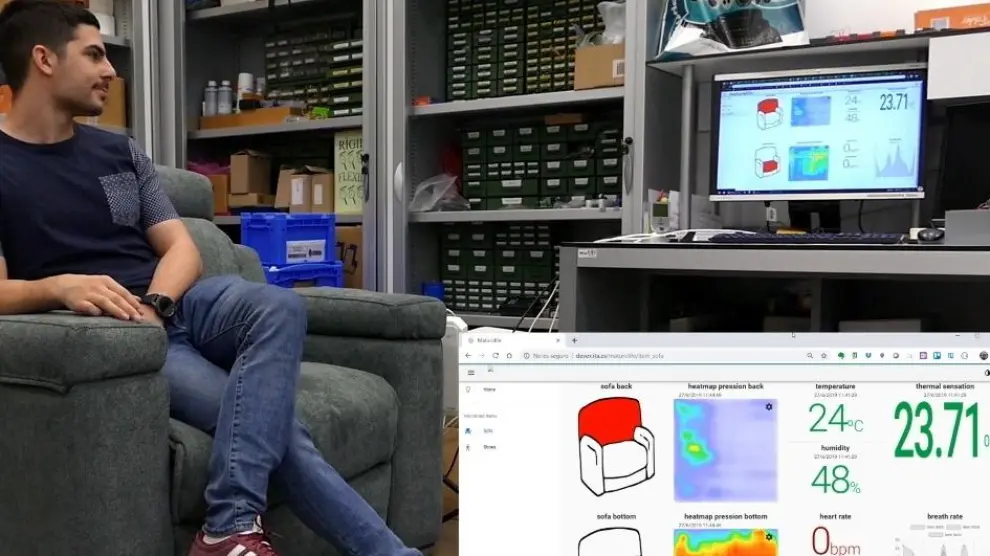
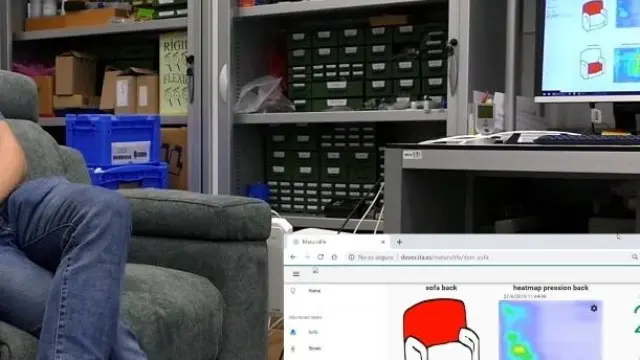
- Maturolife: este otro proyecto europeo (Horizonte 2020), tiene como objetivo el desarrollo de tecnología para la asistencia que permita a personas mayores vivir en entornos urbanos de una manera independiente y cómoda. Para ello introduce sensores que monitorizan su día a día y utilizan los datos para evaluar su estado, guiarles o recomendarles acciones que mejoren su bienestar.
Francisco José Lacueva Big Data y Sistemas Cognitivos. Gestión y Desarrollo de Proyectos de I+D+i. Itainnova
